Elasticsearch
字数: 0 字 时长: 0 分钟

1. 简介
1.1. Elasticsearch
Elasticsearch是由elastic公司开发的一套搜索引擎技术,功能是:存储、搜索、运算
1.2. Kibana
Kibana是由elastic公司提供的用于操作Elasticsearch的可视化控制台,功能有:
- 对Elasticsearch数据的搜索、展示
- 对Elasticsearch数据的统计、聚合,并形成图形化报表、图形
- 对Elasticsearch的集群状态监控
- 它还提供了一个开发控制台(DevTools),在其中对Elasticsearch的Restful的API接口提供了语法提示
elastic技术栈包括:
- Elasticsearch:用于数据存储、计算和搜索
- Logstash/Beats:用于数据收集
- Kibana:用于数据可视化
整套技术栈被称为ELK,经常用来做日志收集、系统监控和状态分析等
2. 安装
2.1. Elasticsearch
因为8以上版本的JavaAPI变化很大,应用不广泛
docker pull elasticsearch:7.12.1docker run -d \
--name es \
-e "ES_JAVA_OPTS=-Xms512m -Xmx512m" \
-e "discovery.type=single-node" \
-v es-data:/usr/share/elasticsearch/data \
-v es-plugins:/usr/share/elasticsearch/plugins \
--privileged \
--network abc-net \
-p 9200:9200 \
-p 9300:9300 \
elasticsearch:7.12.1注意
如果没有abc-net这个网络要先创建:docker network create abc-net
之后访问9200端口,就能看到基础信息啦😄
2.2. Kibana
docker pull kibana:7.12.1docker run -d \
--name kibana \
-e ELASTICSEARCH_HOSTS=http://es:9200 \
--network abc-net \
-p 5601:5601 \
kibana:7.12.1注意
Kibana的版本号要与Elasticsearch的版本对应
之后访问5601端口,就能到控制台界面啦😄
3. 基础知识
3.1. ES采用了倒排索引
MySQL使用的是正向索引
而elasticsearch有如此高性能的搜索表现,正是其倒排索引技术
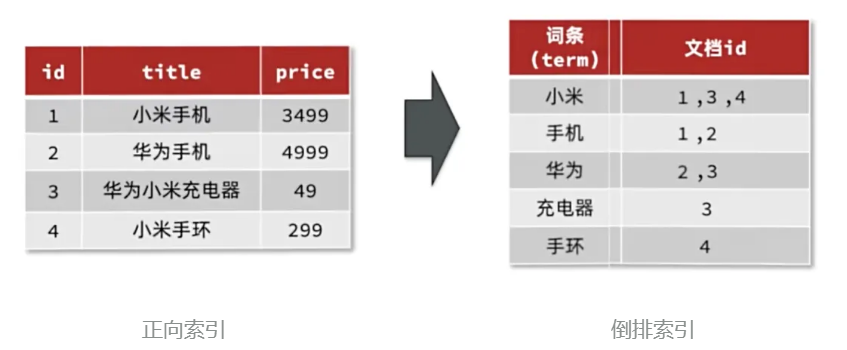
正向索引
正向索引
概念正向索引是最传统的,根据id索引的方式。但根据词条查询时,必须先逐条获取每个文档,然后判断文档中是否包含所需要的词条,是根据文档找词条的过程
优点
- 可以给多个字段创建索引
- 根据索引字段搜索、排序速度非常快
缺点根据非索引字段,或者索引字段中的部分词条查找时,只能全表扫描
搜索流程:对于模糊搜索,需要逐条遍历每行数据,判断是否包含搜索词,如果符合则放入结果集,不符合则丢弃
倒排索引
倒排索引
概念倒排索引则相反,是先找到用户要搜索的词条,根据词条得到词条的文档的id,然后根据id获取文档。是根据词条找文档的过程
优点根据词条搜索、模糊搜索时,速度非常快
缺点
- 只能给词条创建索引,而不是字段
- 无法根据字段做排序
- 文档:每条数据就是一个文档
- 词条:文档按语义分成的词语
建立过程:
- 将每一个文档的数据利用分词算法根据语义拆分,得到一个个词条
- 创建表,每行数据包括词条、词条所在文档id等信息
- 因为词条唯一性,可以给词条创建正向索引
- 此时形成的这张以词条为索引的表,就是倒排索引表
搜索流程:先根据搜索词进行拆分得到词条,根据词条(有索引)到词条列表中查询,得到词条所在文档id,再根据id(有索引)查询文档
3.2. IK分词器
分词器的作用:
- 创建倒排索引时,对文档分词
- 用户搜索时,对输入的内容分词
IK分词器的模式:
- ik_smart:智能切分,粗粒度
- ik_max_word:最细切分,细粒度
安装IK分词器:
- 找到对应的版本下载:

- 查看之前安装的Elasticsearch容器的plugins数据卷目录
docker volume inspect es-plugins- 将IK分词器文件夹上传到"Mountpoint"对应的目录
- 重启es容器即可
docker restart es使用IK分词器:
原先的(默认的)是standard
POST /_analyze
{
"analyzer": "standard",
"text": "我是一个中国人"
}IK提供了两种分词模式ik_smart、ik_max_word
POST /_analyze
{
"analyzer": "ik_max_word",
"text": "我是一个中国人"
}拓展IK分词器词条:
- 在config目录的IkAnalyzer.cfg.xml文件添加拓展词典和停用词典
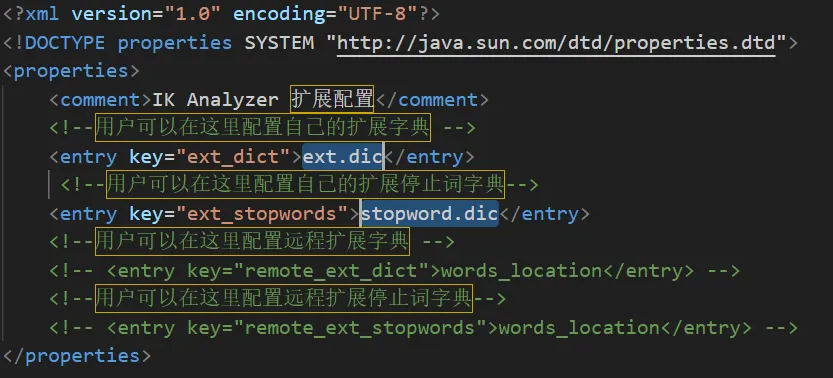
- 在对应词典中添加拓展词条或者停用词条即可
3.3. mysql与elasticsearch关系
| MySQL | Elasticsearch | 说明 |
|---|---|---|
| Table | Index | 索引(index),就是文档的集合,类似数据库的表(table) |
| Row | Document | 文档(Document),就是一条条的数据,类似数据库中的行(Row),文档都是JSON格式 |
| Column | Field | 字段(Field),就是JSON文档中的字段,类似数据库中的列(Column) |
| Schema | Mapping | Mapping(映射)是索引中文档的约束,例如字段类型约束。类似数据库的表结构(Schema) |
| SQL | DSL | DSL是elasticsearch提供的JSON风格的请求语句,用来操作elasticsearch,实现CRUD |
Mysql:擅长事务类型操作,可以确保数据的安全和一致性
Elasticsearch:擅长海量数据的搜索、分析、计算
在实际中,往往是两者结合使用:
- 对安全性要求较高的写操作,使用mysql实现
- 对查询性能要求较高的搜索需求,使用elasticsearch实现
- 两者再基于某种方式,实现数据的同步,保证一致性
3.4. Mapping映射属性
- type:字段数据类型,常见的简单类型有:
- 字符串:text(可分词的文本)、keyword(精确值,例如:品牌、国家、ip地址)
- 数值:long、integer、short、byte、double、float、
- 布尔:boolean
- 日期:date
- 对象:object
- index:是否创建索引,默认为true(像图片url这样的不参 与搜索,应该设置为false)
- analyzer:使用哪种分词器
- properties:该字段的子字段
3.5. 索引库的CRUD
- 创建索引库:PUT /索引库名
- 查询索引库:GET /索引库名
- 删除索引库:DELETE /索引库名
- 添加字段:PUT /索引库名/_mapping
注意
索引库一但创建,是无法修改原有的字段的,但可以添加新字段!
创建索引库
PUT /索引库名称
{
"mappings": {
"properties": {
"字段名":{
"type": "text",
"analyzer": "ik_smart"
},
"字段名2":{
"type": "keyword",
"index": "false"
},
"字段名3":{
"properties": {
"子字段1": {
"type": "keyword"
},
"子字段2": {
"type": "keyword"
},
}
},
}
}
}添加字段
PUT /索引库名/_mapping
{
"properties": {
"新字段名":{
"type": "integer"
}
}
}3.6. 文档的CRUD
- 新增文档:POST /索引库名/_doc/文档id
- 查询文档:GET /索引库名/_doc/文档id
- 删除文档:DELETE /索引库名/_doc/文档id
- 更新文档:
- 全量更新:PUT /索引库名/_doc/文档id
- 局部更新:POST /索引库名/_update/文档id(建议)
全量更新 与 局部更新 的区别
全量更新:先全部删除旧值,再添加新值
局部更新:选择性修改想要修改的字段的值,其他字段值不变
新增文档
POST /索引库名/_doc/文档id
{
"字段1": "值1",
"字段2": "值2",
"字段3": {
"子属性1": "值3",
"子属性2": "值4"
},
}更新文档-全量
PUT /索引库名/_doc/文档id
{
"字段1": "值1",
"字段2": "值2",
}更新文档-局部
POST /索引库名/_update/文档id
{
"doc": {
"字段1": "值1",
"字段2": "值2",
}
}批处理CUD:POST _bulk
批处理-index新增
POST _bulk
{ "index" : { "_index" : "索引库名", "_id" : "文档id" } }
{ "字段1": "值1","字段2": "值2" }
{ "index" : { "_index" : "索引库名", "_id" : "文档id" } }
{ "字段1": "值1","字段2": "值2" }批处理-update更新
POST _bulk
{ "update" : { "_index" : "索引库名", "_id" : "文档id" } }
{ "doc" : {"字段2": "值2"} }批处理-delete删除
POST _bulk
{ "delete" : { "_index" : "索引库名", "_id" : "文档id" } }4. DSL查询
Elasticsearch提供了基于JSON的DSL(Domain Specific Language)语句来定义查询条件,其JavaAPI就是在组织DSL条件
以下是按照json的包含关系写的
4.1. 查询 query
查询所有
GET /索引库名/_search
{
"query": {
"match_all": {}
}
}全文检索查询(Full Text Queries)
用户输入搜索条件先分词,得到词条,然后再利用倒排索引搜索词条
- match:搜索一个字段
- multi_match:同时搜索多个字段,且多个字段都要满足条件
全文检索查询-match
GET /索引库名/_search
{
"query": {
"match": {
"字段名": "搜索条件"
}
}
}全文检索查询-multi_match
GET /索引库名/_search
{
"query": {
"multi_match": {
"query": "搜索条件",
"fields": ["字段1", "字段2"]
}
}
}精确查询(Term-level queries)
根据字段内容精确值匹配
如查找keyword、数值、日期、boolean类型的字段
- term:精准查询
- range:范围查询(gte:大于等于,gt:大于,lte:小于等于,lt:小于)
精确查询-term
GET /索引库名/_search
{
"query": {
"term": {
"字段名": {
"value": "搜索条件"
}
}
}
}精确查询-range
GET /索引库名/_search
{
"query": {
"range": {
"字段名": {
"gte": {最小值},
"lte": {最大值}
}
}
}
}bool查询
组合一个或多个查询子句
- must:必须匹配每个子查询,类似“与”
- should:选择性匹配子查询,类似“或”
- must_not:必须不匹配,不参与算分,类似“非”
- filter:必须匹配,不参与算分
GET /items/_search
{
"query": {
"bool": {
"must": [
{"match": {"name": "手机"}}
],
"should": [
{"term": {"brand": { "value": "vivo" }}},
{"term": {"brand": { "value": "小米" }}}
],
"must_not": [
{"range": {"price": {"gte": 2500}}}
],
"filter": [
{"range": {"price": {"lte": 1000}}}
]
}
}
}注意
出于性能考虑,与搜索关键字无关的查询尽量采用must_not或filter逻辑运算,避免参与相关性算分
算分函数查询
从elasticsearch5.1开始,采用的相关性打分算法是BM25算法
要想控制相关性算分,就要利用 function score 查询
包括:
- 原始查询条件:query部分,基于这个条件搜索文档,并且基于BM25算法给文档打分,原始算分
- 过滤条件:filter部分,符合该条件的文档才会重新算分
- 算分函数:符合filter条件的文档要根据这个函数做运算,得到的函数算分,有四种函数
- weight:函数结果是常量
- field_value_factor:以文档中的某个字段值作为函数结果
- random_score:以随机数作为函数结果
- script_score:自定义算分函数算法
- 运算模式:算分函数的结果、原始查询的相关性算分,两者之间的运算方式有:
- multiply:相乘
- replace:用function score替换query score
- 其它,例如:sum、avg、max、min
GET /item/_search
{
"query": {
"function_score": {
"query": { .... }, // 原始查询,可以是任意条件
"functions": [ // 算分函数
{
"filter": { // 满足的条件,品牌必须是Iphone
"term": {
"brand": "Iphone"
}
},
"weight": 10 // 算分权重为10
}
],
"boost_mode": "multipy" // 加权模式,求乘积
}
}
}4.2. 排序 sort
默认是根据相关度算分(_score)来排序,但是也可以自定义排序方式
但分词字段无法排序,能参与排序字段类型有:keyword类型、数值类型、地理坐标类型、日期类型等
GET /索引库名/_search
{
"query": {
"match_all": {}
},
"sort": [
{
"排序字段1": {
"order": "排序方式1 asc或desc"
},
"排序字段2": {
"order": "排序方式2 asc或desc"
}
}
]
}4.3. 分页 from、size
elasticsearch 默认只返回top10的数据,而如果要查询更多数据就要修改分页参数
基础分页
- from:从第几个文档开始
- size:总共查询几个文档
GET /索引库名/_search
{
"query": {
"match_all": {}
},
"from": 0, // 分页开始的位置,默认为0
"size": 10, // 每页文档数量,默认10
"sort": [
{
"排序字段": {
"order": "排序方式 asc或desc"
}
}
]
}深度分页
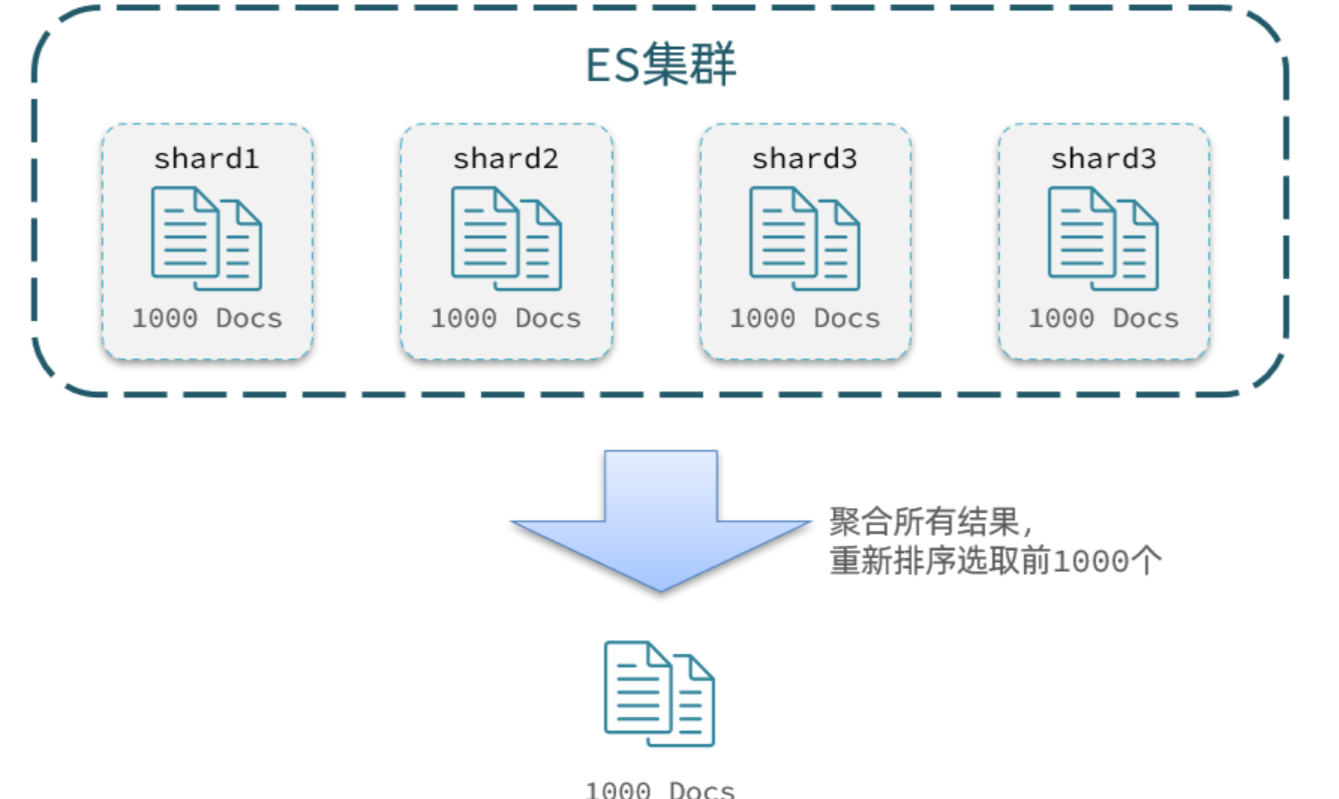
elasticsearch的数据一般会采用分片存储,也就是把一个索引中的数据分成N份,存储到不同节点上。这种存储方式比较有利于数据扩展,但给分页带来了一些麻烦。
比如要得到第99页的数据(假设每页10条),就应该查990~1000的数据,查询方式是查出每一个节点上的前1000名,汇总到一起,得到最终的前1000名,截取990~1000的数据
那要查询第999页的数据呢(假设每页10条),就应该查9990~10000的数据,那么每一个节点都要查前10000条数据,由此往后,会对内存和CPU会产生非常大的压力
∴elasticsearch会禁止from+ size 超过10000的请求
实现深度分页的方式:
search after:分页时需要排序,原理是从上一次的排序值开始,查询下一页数据。参考:
注意
大多数情况下,采用普通分页就可以。百度、京东等网站,其分页都有限制。例如百度最多支持77页,每页不足20条。京东最多100页,每页最多60条
因此,一般我们采用限制分页深度的方式即可,无需实现深度分页!
4.4. 高亮 highlight
GET /索引库名/_search
{
"query": {
"match": {
"搜索字段": "搜索关键字"
}
},
"highlight": {
"fields": {
"高亮字段": {
"pre_tags": "<em>",
"post_tags": "</em>"
}
}
}
}注意
- 设置好标签之后前端指定css样式就可以了(es默认标签就是
<em>) - 当然,也可以直接在后端指定高亮的颜色,修改标签即可:
- 搜索必须有查询条件,而且是全文检索类型的查询条件,例如match
- 参与高亮的字段必须是text类型的字段
4.5. 聚合 aggs
什么是聚合?
聚合(aggregations)可以让我们方便的实现对数据的统计、分析、运算
例如:
- 什么品牌的手机最受欢迎?
- 这些手机的平均价格、最高价格、最低价格?
- 这些手机每月的销售情况如何?
常见的聚合
- 桶(Bucket)聚合:用来对文档做分组
- TermAggregation:按照文档字段值分组,例如按照品牌值分组、按照国家分组
- Date Histogram:按照日期阶梯分组,例如一周为一组,或者一月为一组
- 度量(Metric)聚合:用以计算一些值,如:最大值、最小值、平均值等
- avg:求平均值
- max:求最大值
- min:求最小值
- stats:同时求max、min、avg、sum等
- 管道(pipeline)聚合:其它聚合的结果为基础做进一步运算
GET /索引库名/_search
{
"size": 0, //使结果中不包含文档,只包含聚合
"aggs": {
"自定义的聚合名称": {
"聚合的类型": { //term/range……
"field": "参与聚合的字段",
"size": 20 //返回的聚合结果的最大数量
},
"aggs": { //在以上的基础上再次聚合
"自定义的聚合名称": {
"Metric聚合的类型": {
"field": "参与聚合的字段"
}
}
}
}
}
}注意
参加聚合的字段必须是keyword、日期、数值、布尔类型
聚合的三要素:
- 聚合名称
- 聚合类型
- 聚合字段
聚合可配置属性:
- size:指定聚合结果数量
- order:指定聚合结果排序方式
- field:指定聚合字段
5. 在java中使用(7.x)
5.1. 集成
- 引入依赖
<dependency>
<groupId>org.springframework.data</groupId>
<artifactId>spring-data-elasticsearch</artifactId>
<version>4.4.18</version>
</dependency>- 配置yml文件
spring:
elasticsearch:
uris: http://192.168.174.128:92005.2. 案例
要求:将数据库的数据同步到es中,并通过各种条件(模糊搜索、排序)从es查询信息
我用的springboot版本是2.7.6
- 创建es的索引库
import com.fasterxml.jackson.annotation.JsonFormat;
import lombok.Builder;
import lombok.Data;
import org.springframework.data.annotation.Id;
import org.springframework.data.elasticsearch.annotations.Document;
import org.springframework.data.elasticsearch.annotations.Field;
import org.springframework.data.elasticsearch.annotations.FieldType;
import java.io.Serial;
import java.io.Serializable;
import java.util.Date;
import java.util.List;
@Document(indexName = "user_test") //将来在es中创建的索引库的名称
@Data
@Builder
public class UserDoc implements Serializable {
private static final String DATE_TIME_PATTERN="yyyy-MM-dd HH:mm:ss";
@Serial
private static final long serialVersionUID = 1L;
@Id
private Long id;
@Field(type = FieldType.Keyword)
private String userName;
@Field(type = FieldType.Keyword)
private String email;
@Field(type = FieldType.Keyword)
private String phone;
@Field(type = FieldType.Text,analyzer = "ik_max_word") //analyzer指定分词器
private String nickName;
@Field(type = FieldType.Text,index = false)
private String avatar;
@Field(type = FieldType.Text,index = false)
private String background;
@Field(type = FieldType.Text,analyzer = "ik_max_word")
private String introduce;
@Field(type = FieldType.Object,enabled = false)
private Object extJson;
private List<String> roles;
private List<String> permissions;
@JsonFormat(pattern = DATE_TIME_PATTERN,timezone = "Asia/Shanghai")
@Field(type= FieldType.Date,format = {},pattern = DATE_TIME_PATTERN)
private Date createdTime;
@JsonFormat(pattern = DATE_TIME_PATTERN,timezone = "Asia/Shanghai")
@Field(type= FieldType.Date,format = {},pattern = DATE_TIME_PATTERN)
private Date updatedTime;
@Field(type = FieldType.Keyword)
private Integer isDelete;
}- 将数据库数据同步到es中
这里仅用于演示,使用全量同步的方式
import com.qit.softwarestudio.search.doc.UserDoc;
import org.springframework.boot.CommandLineRunner;
import org.springframework.stereotype.Component;
import com.qit.softwarestudio.search.mapper.UserEsMapper;
@Component
public class FullSyncUserToEs implements CommandLineRunner {
@Resource
private UserEsMapper userEsMapper;
@Override
public void run(String... args) throws Exception {
//从数据库查数据,转化为es的文档对象(UserDoc.class)
}
final int pageSize = 500;
int total = userDocs.size();
log.info("UserService.list() 共 [{}] 条数据", total);
for (int i = 0; i < total; i++) {
int end = Math.min(i + pageSize, total);
userEsMapper.saveAll(userDocs.subList(i, end));
}
log.info("UserService.list() 全量同步完成");
}
}其中 UserEsMapper 继承了 ElasticsearchRepository
import com.qit.softwarestudio.search.doc.UserDoc;
import org.springframework.data.elasticsearch.repository.ElasticsearchRepository;
public interface UserEsMapper extends ElasticsearchRepository<UserDoc, Long> {
}- 编写controller接口
这里我以ddd的方式来写,层次结构如下:
SearchController->SearchDomainService->SearchDomainServiceImpl->SearchService->SearchServiceImpl
import com.qit.softwarestudio.common.resp.BaseResponse;
import com.qit.softwarestudio.common.resp.ResponseCode;
import com.qit.softwarestudio.common.utils.ResultUtil;
import com.qit.softwarestudio.search.aggregate.GlobalSearchAggregate;
import com.qit.softwarestudio.search.constant.Constant;
import com.qit.softwarestudio.search.convert.GlobalSearchAdapterConvert;
import com.qit.softwarestudio.search.dto.request.GlobalSearchRequestDTO;
import com.qit.softwarestudio.search.dto.response.PageResponseDTO;
import com.qit.softwarestudio.search.service.SearchDomainService;
import lombok.extern.slf4j.Slf4j;
import org.springframework.validation.annotation.Validated;
import org.springframework.web.bind.annotation.PostMapping;
import org.springframework.web.bind.annotation.RequestBody;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import javax.annotation.Resource;
@RestController
@RequestMapping("/search")
@Slf4j
public class SearchController {
@Resource
private SearchDomainService searchDomainService;
@PostMapping("/global")
public BaseResponse<PageResponseDTO<?>> globalSearch(@Validated @RequestBody GlobalSearchRequestDTO globalSearchRequestDTO) {
try {
String type = globalSearchRequestDTO.getType();
if (!(Constant.TYPE.QUESTION.equals(type) || Constant.TYPE.USER.equals(type))) {
throw new IllegalArgumentException("searchType must be either 'question' or 'user'");
}
GlobalSearchAggregate globalSearchAggregate = GlobalSearchAdapterConvert.INSTANCE.convertToAggregate(globalSearchRequestDTO);
PageResponseDTO<?> responseDTO = searchDomainService.globalSearch(globalSearchAggregate);
return ResultUtil.success(responseDTO);
} catch (Exception e) {
return ResultUtil.fail(ResponseCode.SYSTEM_ERROR);
}
}
}import lombok.Getter;
import javax.validation.constraints.Max;
import javax.validation.constraints.Min;
import javax.validation.constraints.NotBlank;
import java.io.Serial;
import java.io.Serializable;
import java.util.Map;
@Getter
public class GlobalSearchRequestDTO implements Serializable {
@Serial
private static final long serialVersionUID = 1L;
/** 页数 */
@Min(value = 1, message = "pageNum >= 0")
private int pageNum = 1;
/** 条数 */
@Min(value = 1, message = "pageSize >= 1")
@Max(value = 30, message = "pageSize <= 30")
private int pageSize = 10;
/** 输入的文本 */
private String searchText;
/** 特征标识区分字段 */
@NotBlank(message = "type类型不能为空")
private String type;
/** 排序字段,排序条件(默认降序,asc/desc,大小写均可)*/
private Map<String, String> sortMap;
}- 在domain层进行信息处理,将es的搜索结果转为自定义的返回结果
import com.qit.softwarestudio.search.aggregate.GlobalSearchAggregate;
import com.qit.softwarestudio.search.convert.GlobalSearchDomainConvert;
import com.qit.softwarestudio.search.doc.QuestionDoc;
import com.qit.softwarestudio.search.doc.UserDoc;
import com.qit.softwarestudio.search.dto.response.PageResponseDTO;
import com.qit.softwarestudio.search.entity.GlobalSearchEntity;
import com.qit.softwarestudio.search.service.SearchDomainService;
import com.qit.softwarestudio.search.service.SearchService;
import org.springframework.data.elasticsearch.core.SearchHit;
import org.springframework.data.elasticsearch.core.SearchHits;
import org.springframework.stereotype.Service;
import javax.annotation.Resource;
import java.util.ArrayList;
import java.util.List;
@Service
public class SearchDomainServiceImpl implements SearchDomainService {
@Resource
private SearchService searchService;
@Override
public PageResponseDTO<?> globalSearch(GlobalSearchAggregate globalSearchAggregate) {
GlobalSearchEntity globalSearchEntity = GlobalSearchDomainConvert.INSTANCE.convertToEntity(globalSearchAggregate);
switch (globalSearchEntity.getType()){
case "user"->{
return searchUser(globalSearchEntity);
}
case "question"->{
return searchQuestion(globalSearchEntity);
}
default -> {
return null;
}
}
}
private PageResponseDTO<UserDoc> searchUser(GlobalSearchEntity globalSearchEntity) {
SearchHits<UserDoc> searchHits = searchService.searchUser(globalSearchEntity);
PageResponseDTO<UserDoc> page = new PageResponseDTO<>();
page.setTotal(searchHits.getTotalHits());
page.setPages((long) Math.ceil((double) searchHits.getTotalHits() / globalSearchEntity.getPageSize()));
//处理结果
ArrayList<UserDoc> resourceList = new ArrayList<>();
if (searchHits.hasSearchHits()){
List<SearchHit<UserDoc>> searchHitList = searchHits.getSearchHits();
for (SearchHit<UserDoc> searchHit : searchHitList) {
UserDoc source = searchHit.getContent();
String newUserName = searchHit.getHighlightField("userName").toString();
String newNickName = searchHit.getHighlightField("nickName").toString();
String newIntroduce = searchHit.getHighlightField("introduce").toString();
UserDoc userDoc = UserDoc.builder() //如果设置了高亮字段,则使用高亮结果代替原来结果
.userName("[]".equals(newUserName) ? source.getUserName() : newUserName.substring(1, newUserName.length() - 1))
.nickName("[]".equals(newNickName) ? source.getNickName() : newNickName.substring(1, newNickName.length() - 1))
.introduce("[]".equals(newIntroduce) ? source.getIntroduce() : newIntroduce.substring(1, newIntroduce.length() - 1))
.email(source.getEmail())
.phone(source.getPhone())
.avatar(source.getAvatar())
.background(source.getBackground())
.extJson(source.getExtJson())
.roles(source.getRoles())
.permissions(source.getPermissions())
.id(source.getId())
.createdTime(source.getCreatedTime())
.updatedTime(source.getUpdatedTime())
.isDelete(source.getIsDelete())
.build();
resourceList.add(userDoc);
}
}
page.setData(resourceList);
return page;
}
}搜索结果统一响应类
import lombok.Data;
import java.util.List;
@Data
public class PageResponseDTO<T> {
private Long total; //总条数
private Long pages; //总页数
private List<T> data; //数据集合
}- 在infrastructure层编写es搜索的具体实现
import com.qit.softwarestudio.search.doc.QuestionDoc;
import com.qit.softwarestudio.search.doc.UserDoc;
import com.qit.softwarestudio.search.entity.GlobalSearchEntity;
import lombok.extern.slf4j.Slf4j;
import org.elasticsearch.index.query.BoolQueryBuilder;
import org.elasticsearch.index.query.QueryBuilders;
import org.elasticsearch.search.fetch.subphase.highlight.HighlightBuilder;
import org.elasticsearch.search.sort.FieldSortBuilder;
import org.elasticsearch.search.sort.SortBuilder;
import org.elasticsearch.search.sort.SortBuilders;
import org.elasticsearch.search.sort.SortOrder;
import org.springframework.data.domain.PageRequest;
import org.springframework.data.elasticsearch.core.ElasticsearchRestTemplate;
import org.springframework.data.elasticsearch.core.SearchHits;
import org.springframework.data.elasticsearch.core.query.NativeSearchQuery;
import org.springframework.data.elasticsearch.core.query.NativeSearchQueryBuilder;
import org.springframework.stereotype.Service;
import javax.annotation.Resource;
import java.util.ArrayList;
import java.util.List;
import java.util.Map;
@Service
@Slf4j
public class SearchServiceImpl implements SearchService {
@Resource
private ElasticsearchRestTemplate elasticsearchRestTemplate;
@Override
public SearchHits<UserDoc> searchUser(GlobalSearchEntity globalSearchEntity) {
//构建查询条件
NativeSearchQuery searchQuery = getSearchQuery(globalSearchEntity);
//从es查询数据
SearchHits<UserDoc> searchHits = elasticsearchRestTemplate.search(searchQuery, UserDoc.class);
//返回
return searchHits;
}
/**
* 构建通用查询条件
*/
private NativeSearchQuery getSearchQuery(GlobalSearchEntity globalSearchEntity) {
String type = globalSearchEntity.getType();
String text = globalSearchEntity.getSearchText();
int pageNum = globalSearchEntity.getPageNum();
int pageSize = globalSearchEntity.getPageSize();
Map<String, String> sortMap = globalSearchEntity.getSortMap();
//构造查询条件
BoolQueryBuilder boolQueryBuilder = QueryBuilders.boolQuery();
//过滤
boolQueryBuilder.filter(QueryBuilders.termQuery("isDelete", 0));
//按关键词检索
if (text != null && !text.isEmpty()) {
addShouldConditions(boolQueryBuilder,text,type);
}
//高亮
HighlightBuilder highlightBuilders = createHighlightBuilders(type);
//排序
List<SortBuilder<?>> sortBuilders = new ArrayList<>();
if (sortMap != null && !sortMap.isEmpty()) {
sortMap.forEach((k, v) -> {
if (k != null && !k.isEmpty()) {
FieldSortBuilder fieldSortBuilder = SortBuilders.fieldSort(k);
fieldSortBuilder.order(v.isEmpty()?SortOrder.DESC:SortOrder.valueOf(v.toUpperCase()));//默认降序
sortBuilders.add(fieldSortBuilder);
}
});
} else {
// 默认按相关性评分排序
sortBuilders.add(SortBuilders.scoreSort());
}
//分页
PageRequest pageRequest = PageRequest.of(pageNum - 1, pageSize);
//构造查询
return new NativeSearchQueryBuilder()
.withQuery(boolQueryBuilder)
.withPageable(pageRequest)
.withSorts(sortBuilders)
.withHighlightBuilder(highlightBuilders)
.build();
}
/**
* 添加检索条件
*/
private void addShouldConditions(BoolQueryBuilder boolQueryBuilder, String text, String type) {
switch (type){
case "user":
boolQueryBuilder.should(QueryBuilders.matchQuery("userName", text));
boolQueryBuilder.should(QueryBuilders.matchQuery("nickName", text));
boolQueryBuilder.should(QueryBuilders.matchQuery("introduce", text));
boolQueryBuilder.minimumShouldMatch(1);
break;
case "question":
boolQueryBuilder.should(QueryBuilders.matchQuery("title", text));
boolQueryBuilder.should(QueryBuilders.matchQuery("content", text));
boolQueryBuilder.should(QueryBuilders.matchQuery("answer", text));
boolQueryBuilder.minimumShouldMatch(1);
break;
default:
boolQueryBuilder.should();
}
}
/**
* 构造高亮字段
*/
private HighlightBuilder createHighlightBuilders(String type) {
return switch (type) {
case "user" -> addHighlightFields("userName", "nickName","introduce");
case "question" -> addHighlightFields("title", "content","answer");
default -> throw new IllegalStateException("Unexpected value: " + type);
};
}
private HighlightBuilder addHighlightFields(String... highlightField) {
HighlightBuilder highlightBuilder = new HighlightBuilder().preTags("<span style='color:red'>").postTags("</span>");
for (String cr : highlightField) {
highlightBuilder.field(cr);
}
return highlightBuilder;
}
}至此,我们已经完成了一个简单的搜索功能,你可以根据自己的需求进行扩展
6. 性能优化
6.1 批量导入
可以从以下几方面加快数据导入es的速度
- 减少刷新频率(HZ)
- 默认是1s,写入量很大时吞吐量降低,可以考虑插入时降低频率/关掉,等插入结束后再回复
- 最佳bulk数量
- 通过测试得到对应环境的bulk数量最佳值,每次插入100,200,……
- 使用多线程
- 多线程并发写入
- 自动生成id
- 手动设置id的话,插入时会判断该id是否已经存在,耗费时间;如果需要保存数据库id字段,可以考虑添加一个id字段,而不是用es的id
🥳 将来的你,一定会感谢现在努力奋斗的你,加油!💯